
We aren't going back
Yep, another one about LLMs and Agents

Over the weekend, I prototyped four more apps.
Firstly - this fact continues to astound me. I can’t believe that I can, basically, program at a higher level of abstraction now. Years ago at Bloc I recall a particularly hard time trying to figure out the best methodology to employ when instructing students in programming. I remember thinking back to my own learning journey - QBasic. I could just open up QBASIC, type some code, and hit run. It would run or error. And the language was so simple - I never really got confused about lexical scoping, classes, or confusing syntax, things that often trip up newbies today. And I remember (and still think) the utter lack of a modern equivalent has held back tech education immensely. Why wouldn’t someone build the modern qbasic? Is there a subset of javascript that would fit the bill?
Well, I remember thinking: why don’t we try this? But alas, we were not in the business of creating new languages, we were in the business of teaching students programming and getting them jobs.
So, it strikes me that now, this new world does actually sorta bypass the hard parts of learning programming. If I have a crude understanding of the high-level pieces of an app - views, components, state, persistence, I really am able to build working software now without cracking open the code editor and manually running my build cycle like a caveman. Even the mighty REPL doesn’t stand a chance.
One of the fundamental insights I’ve learned recently is how important context is for the coding LLM. Just cracking open Aider or Replit and saying “build me a podcast app” will not get the job done. It might get pretty far - but it won’t get the job done. I’ve routinely found that comparing LLM agents with perfect supercomputers is not the right approach. Instead, comparing them with real human engineers works far better. And by that - I don’t mean treating them with respect (although interestingly I do that instinctually, which is probably a combo of anthropomorphism and fear of Skynet waking up and remembering all of our interactions).
What I mean is that they make human mistakes. The same mistakes a junior-ish software engineer on a team will make.
Without context, they will make assumptions without surfacing them. And it will have been my fault for not specifying it more clearly. They will explore technical paths that might turn out to be dead ends and have to start over. They will sometimes get confused and implement the wrong thing, or the right thing the wrong way. Or even a quirky way. And, without guidance on how to write code that is maintainable (and what does that even mean?) you’ve got a 50/50 chance it will do so.
So I’ve started working a lot more beforehand on PRDs (Product Requirement Doc) and SDDs (Software Design Doc).
At first I wrote these by hand. As every good PM knows, this is a lot of work, and it’s hard to get right. Impossible to get right. As I went along, I realized - DOH. Why am I not using ChatGPT to write these?
BINGO.
The iteration speed skyrocketed, as did the quality of the code produced. I switch back and forth from ChatGPT to obsidian (where I keep all my prompts, responses, code samples, etc). Once I am happy with a prompt, I copy it into Aider or Replit and go.
The fact that this works so, so well really has me thinking hard. What other aspects of our process require strictly human input, and how? And what are subject to this extraordinary optimization?
I remembered a slide deck from many, many years ago from a presentation Adam Wiggins made (who was an advisor for us at Bloc, and for whom I am grateful to have learned a bit from) called An Engineer’s Guide to Working with product managers. I hope he will be OK with me linking to the deck here, as it is something I learned a lot from as an early 20s founder/engineer thrust into a leadership role at a growing startup:
From slide 18, here is the lifecycle that I hold in my head whenever I am managing, leading, designing, or coding a software project or team:
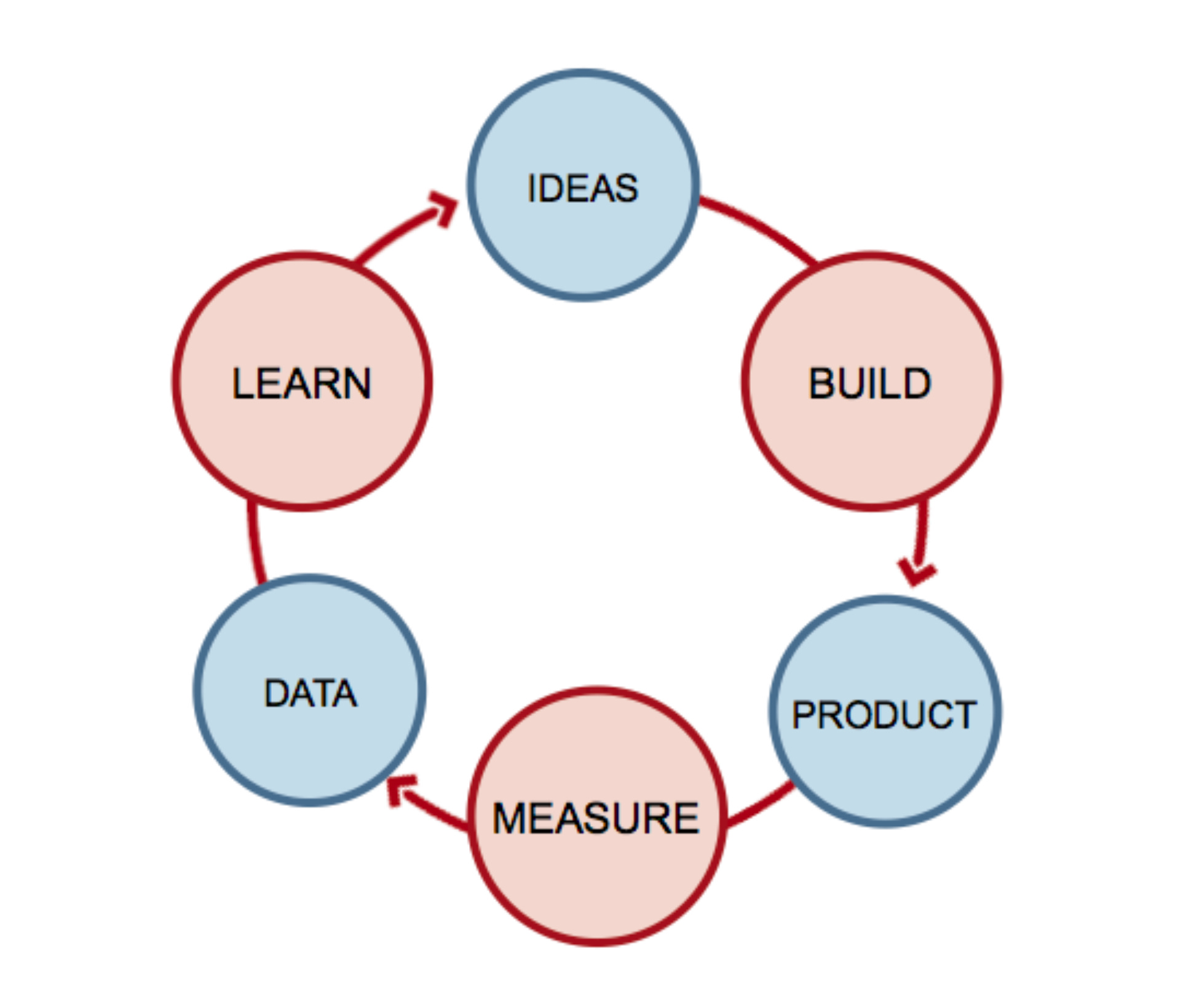
I once heard someone say that the hard parts of a diagram like this aren’t the nodes but the edges. And these edges aren’t named. And it strikes me that the stuff I’ve been doing with LLMs is aimed directly at those edges.
What happens between “Ideas” and “Build”?
The hard work of synthesizing those ideas into requirements, that’s what. Now, with this cycle in my head, I wonder what other parts of the cycle can and will be augmented with these new tools.
In established companies, most of these steps happen between people, or even teams of people. Each step might have a different role. And at startups, the founders have to do all of it.
I think this partially explains vibe coding. The feedback loop in a key part of the experience has been tightened immensely, especially if you aren’t yet at product market fit and you’re searching for the right problem to solve, or the right way to solve it. Until you have product market fit, code quality doesn’t matter. After you have product market fit, it’s….pretty important.
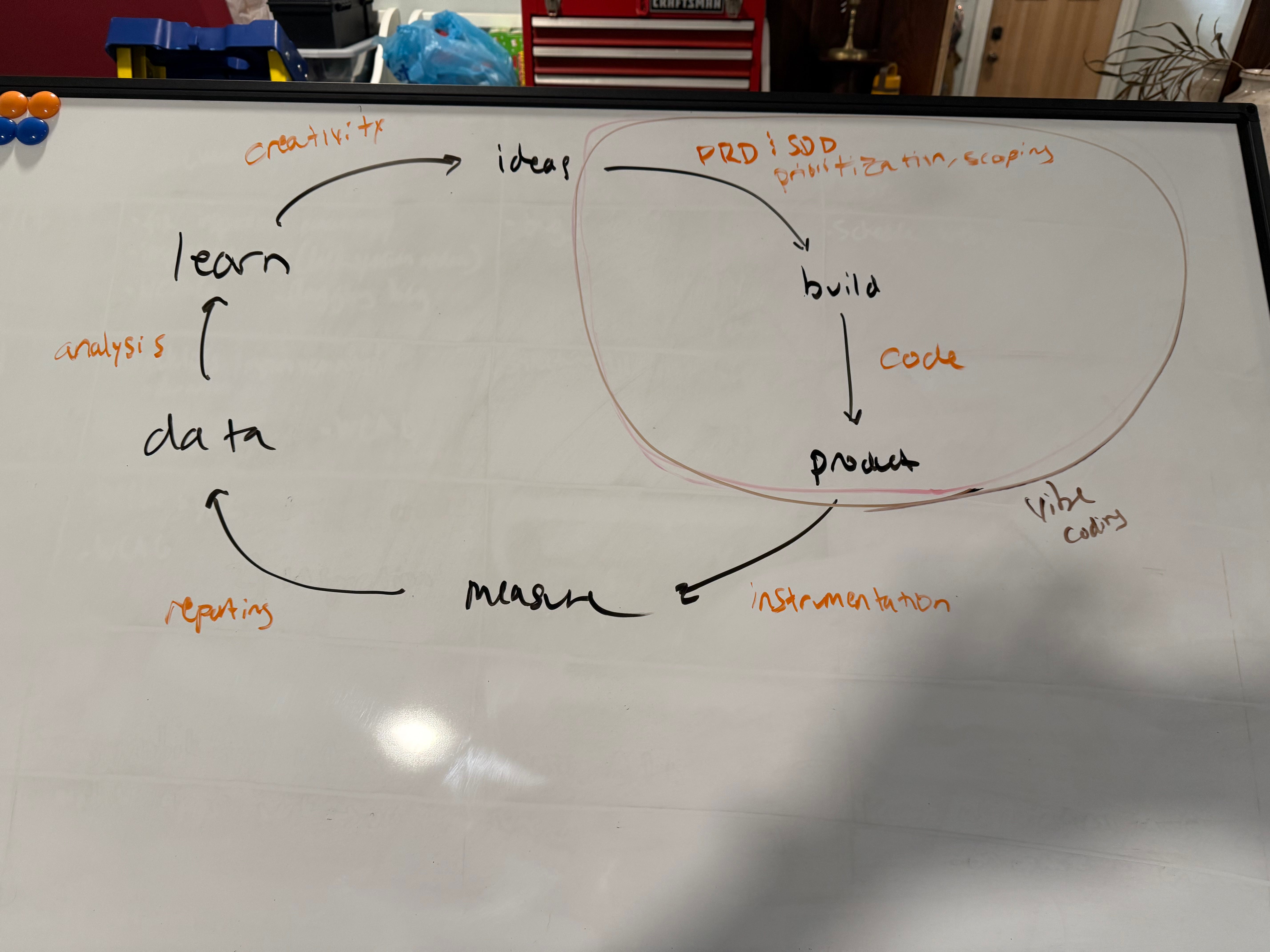
After spending some time this weekend “vibe coding”, it is addicting. It’s the same kind of addicting as building software, except more so. I’m still reading unhandled exceptions, I’m still thinking about system architecture, and I’m still waiting on the build step. But I’m doing it at like…10x the speed. It’s truly nuts.
I should also note that the approach for existing software, changing software that’s been around for a decade, seems like a different beast to me. Maybe we just need to wait until our context windows grow large enough, large enough to fit an entire codebase, its history, documentation, etc. Combined with better models…..it’s tough to say.
I do not think good engineers will be replaced. There is still no way, I think, to gain the kind of time leverage I’m currently experiencing without a fundamental understanding of how software works and what the development lifecycle is like as a participant.
But I do think that this is going to change things. It already has.
“The future has arrived — it’s just not evenly distributed yet.”
William Gibson
The hype has kinda died down for me. Like you said it's a different beast. Vibe coding is fun for prototyping and MVPs, but it ultimately kinda slows me down in the long run. It really reminds m of circa-2012 when I would build clickable prototypes in InVision and think that the future was incredible. It became a good part of most flows but it didn't replace coders or anything.
As someone with considerable experience with software development, you can effectively communicate your requirements to the AI, spot its mistakes, debug the communication gap, and try again.
Folks just entering the field lack that experience. AI replaces many of the tasks required to gain that experience. Writing a bunch of low-quality code and having a senior engineer critique it is a rite of passage that leads to improvement.
Do you see a danger in companies neglecting to invest in new talent since it may be more effective and certainly much cheaper to have a few seniors with AI superpowers than a few seniors with a team of juniors?
Will tech giants be the only ones with the resources to train new talent?
How do you see all this playing out over the next few years?